%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Diffusion Models
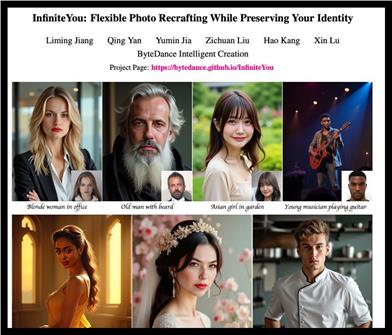
Infiniteyou
InfiniteYou (InfU) is a powerful diffusion-transformer-based framework designed for flexible image reconstruction while preserving user identity. By introducing identity features and employing a multi-stage training strategy, it significantly improves the quality and aesthetics of image generation while enhancing text-to-image alignment. This technology is important for improving the similarity and aesthetics of image generation and is suitable for various image generation tasks.
Image Generation
76.7K
On Device Sora
On-device Sora is an open-source project aimed at enabling efficient video generation on mobile devices (such as the iPhone 15 Pro) using technologies like Linear Proportional Jump (LPL), Time Dimension Tag Merging (TDTM), and Concurrent Inference with Dynamic Loading (CI-DL). Developed from the Open-Sora model, it generates high-quality videos based on text input. Its main advantages include efficiency, low power consumption, and optimization for mobile devices. This technology is applicable in scenarios that require rapid video creation on mobile devices, such as short video production and advertising. The project is currently open source and can be used free of charge.
Video Production
49.4K

Diffsplat
DiffSplat is an innovative 3D generation technology that quickly creates 3D Gaussian point clouds from text prompts and single-view images. This technology leverages a large-scale pre-trained text-to-image diffusion model to efficiently generate 3D content. It addresses the limitations of traditional 3D generation methods concerning dataset size and the ineffective use of 2D pre-trained models, while maintaining 3D consistency. Key advantages of DiffSplat include efficient generation speeds (completed in 1 to 2 seconds), high-quality 3D output, and support for various input conditions. The model has broad prospects in academic research and industrial applications, particularly in scenarios requiring the rapid generation of high-quality 3D models.
3D Modeling
50.2K

Go With The Flow
Go with the Flow is an innovative video generation technology that achieves efficient control over video diffusion model motion patterns by utilizing distorted noise instead of traditional Gaussian noise. This technology allows for precise control of object and camera movements in videos without modifying the original model architecture, all while maintaining computational efficiency. Key advantages include high efficiency, flexibility, and scalability, making it applicable across various scenarios, such as image-to-video and text-to-video generation. Developed by researchers from institutions like Netflix Eyeline Studios, it offers significant academic value and commercial potential, and is currently available to the public as an open-source tool.
Video Production
58.5K
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRA is a deep learning-based text-to-image generation model designed to generate high-quality images from natural language descriptions. Built on a Diffusion architecture and incorporating LoRA technology, it enables efficient fine-tuning and stylized image generation. Its main advantages include high-resolution output, diverse style support, and excellent performance in complex scenes. This model is intended for users who need high-quality image generation, such as designers, artists, and content creators, facilitating the rapid realization of their creative concepts.
Image Generation
63.8K

Tokenverse
TokenVerse is an innovative multi-concept personalization method leveraging a pre-trained text-to-image diffusion model. It can decouple complex visual elements and attributes from a single image, enabling seamless generation of combined concepts. This approach transcends the existing technological limitations regarding concept types or diversity, supporting various concepts including objects, accessories, materials, poses, and lighting. The significance of TokenVerse lies in its ability to provide more flexible and personalized solutions in the field of image generation, catering to diverse user needs across different scenarios. Although the code for TokenVerse has not been made public yet, its potential for personalized image generation has garnered significant attention.
Image Generation
60.7K
Chinese Picks
Hunyuan3d 2.0
Hunyuan3D 2.0 is an advanced large-scale 3D synthesis system developed by Tencent, focusing on generating high-resolution textured 3D assets. The system comprises two core components: the large-scale shape generation model Hunyuan3D-DiT and the large-scale texture synthesis model Hunyuan3D-Paint. By decoupling the challenges of shape and texture generation, it provides users with a flexible platform for 3D asset creation. The system surpasses existing open-source and closed-source models in geometric details, conditional alignment, texture quality, and more, showcasing high practicality and innovation. Currently, the inference code and pre-trained models of this model are open-sourced, allowing users to quickly experience it through the official website or Hugging Face space.
3D Modeling
153.5K
Seedvr
SeedVR is an innovative diffusion transformer model specifically created for addressing real-world video restoration tasks. Its unique shifted window attention mechanism allows it to efficiently process video sequences of arbitrary length and resolution. The design of SeedVR has significantly enhanced both its generative capabilities and sampling efficiency, outperforming traditional diffusion models in both synthesis and real-world benchmarks. Moreover, SeedVR incorporates modern practices such as causal video autoencoders, mixed image and video training, and progressive training, further enhancing its competitiveness in the field of video restoration. As a cutting-edge video restoration technology, SeedVR provides video content creators and post-production professionals with a powerful tool that can significantly improve video quality, especially when working with low-quality or damaged video materials.
Video Editing
50.5K
Vmix
VMix is a technology for improving the aesthetic quality of text-to-image diffusion models through an innovative conditional control method—Value-Mixing Cross-Attention—that systematically enhances the aesthetic presentation of images. As a plug-and-play aesthetic adapter, VMix enhances the quality of generated images while maintaining the generality of visual concepts. The core insight behind VMix is to design a superior conditional control method that enhances the aesthetic performances of existing diffusion models while ensuring alignment between images and text. VMix is flexible enough to be applied to community models for better visual performance without the need for retraining.
Image Generation
48.9K
Diffsensei
DiffSensei is a customized comic generation model that combines multimodal large language models (LLMs) with diffusion models. It can generate controllable black-and-white comic panels based on user-provided text prompts and character images, featuring flexible character adaptability. The importance of this technology lies in its integration of natural language processing and image generation, opening up new possibilities for comic creation and personalized content generation. The DiffSensei model has gained attention due to its high-quality image generation, diverse application scenarios, and efficient resource utilization. Currently, the model is publicly available for free download on GitHub, though specific usage may require adequate computational resources.
AI design tools
96.3K
Invsr
InvSR is a diffusion inversion-based image super-resolution technology that leverages the rich image priors from large pre-trained diffusion models to enhance super-resolution performance. This technology constructs intermediate states of the diffusion model through a partial noise prediction strategy, serving as starting sampling points, while employing a deep noise predictor to estimate an optimal noise map, thus initializing sampling during the forward diffusion process to generate high-resolution results. InvSR supports any number of sampling steps, ranging from one to five, and even demonstrates performance superior to or comparable with existing state-of-the-art methods when using just a single sampling step.
Image Enhancement
62.7K
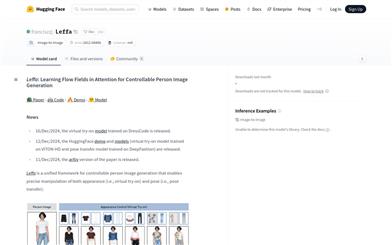
Leffa
Leffa is a unified framework for controllable character image generation that allows for precise control over character appearance (e.g., virtual fitting) and pose (e.g., pose transfer). The model minimizes detail distortion and maintains high image quality by guiding target queries to relevant areas in the reference images during training. Key advantages of Leffa include model agnosticism, enabling performance enhancement of other diffusion models.
AI design tools
79.8K
Comfyui HelloMeme
HelloMeme is an integrated diffusion model featuring Spatial Knitting Attention, designed to embed high-level and richly detailed conditions. The model supports image and video generation, offering advantages such as improved expression consistency between generated and driven videos, reduced VRAM usage, and optimized algorithms. Developed by the HelloVision team, a part of HelloGroup Inc., HelloMeme represents cutting-edge technology in image and video generation with significant commercial and educational value.
Video Production
67.3K
Color Diffusion
Color-diffusion is an image coloring project based on diffusion models that utilizes the LAB color space to colorize black and white images. The main advantage of this project lies in its ability to use existing grayscale information (L channel) to predict color information (A and B channels) through model training. This technique is significant in the field of image processing, especially in restoring old photographs and artistic creation. As an open-source project, Color-diffusion was quickly developed by the author to satisfy curiosity and gain experience in training a diffusion model from scratch. The project is currently free and has considerable room for improvement.
Image Editing
52.2K

Diffusion Self Distillation
Diffusion Self-Distillation is a self-distillation technique based on diffusion models for zero-shot custom image generation. This technology allows artists and users to generate their own datasets via a pre-trained text-to-image model without requiring large paired datasets, enabling them to fine-tune the model for image-to-image tasks conditioned on text and images. This approach surpasses existing zero-shot methods in maintaining performance on identity generation tasks and can rival instance-based tuning techniques without the need for optimization during testing.
Image Generation
102.9K
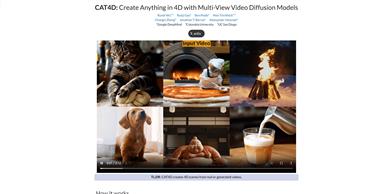
CAT4D
CAT4D is a cutting-edge technology that generates 4D scenes from monocular videos using multi-view video diffusion models. It transforms input monocular videos into multi-perspective video and reconstructs dynamic 3D scenes. The significance of this technology lies in its ability to extract and reconstruct complete spatial and temporal information from single-view video footage, providing robust technical support for virtual reality, augmented reality, and 3D modeling. Background information indicates that CAT4D is a collaborative project developed by researchers from Google DeepMind, Columbia University, and UC San Diego, representing a successful case of turning advanced research outcomes into practical applications.
3D Modeling
60.2K
Mikudance
MikuDance is a diffusion-based animation generation pipeline that combines blended motion dynamics to animate stylized character art. The technology addresses the challenges of high dynamic movement and reference guide misalignment in character art animations through two key techniques: blended motion modeling and mixed control diffusion. MikuDance explicitly models dynamic camera movements in pixel-level space using scene motion tracking strategies, achieving unified character-scene motion modeling. On this foundation, mixed control diffusion implicitly aligns different character scales and body types, allowing for flexible control of localized character movements. Additionally, a motion-adaptive normalization module is incorporated to effectively inject global scene movement, paving the way for comprehensive character art animation. Through extensive experiments, MikuDance demonstrates its effectiveness and generative capabilities across various character arts and motion guides, consistently producing high-quality animations with significant motion dynamics.
Character Art
50.0K
Seededit
SeedEdit is a large diffusion model introduced by the Doubao Team, designed to revise images based on any text prompts. It achieves an optimal balance between image reconstruction and regeneration by aligning a powerful image generator with a robust image editor in a stepwise fashion. SeedEdit enables zero-shot stable editing of high aesthetic/resolution images and supports continuous revision of images. The significance of this technology lies in its ability to address the core challenge of scarcity of paired image data in image editing problems, by viewing the text-to-image (T2I) generation model as a weak editing model and achieving 'editing' by generating new images with new prompts, which are then distilled and aligned within an image-conditioned editing model.
Image Editing
205.6K
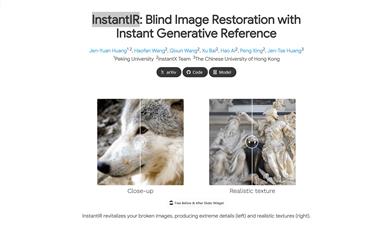
Instantir
InstantIR is a blind image restoration method based on diffusion models that can handle unknown degradation problems during testing, enhancing the model's generalization capabilities. This technology dynamically adjusts generation conditions by generating reference images during inference, thereby providing robust generation conditions. Key advantages of InstantIR include the ability to restore details in extremely degraded images, delivering realistic textures, and enabling creative image restoration through text descriptions. This technology has been jointly developed by researchers from Peking University, the InstantX team, and The Chinese University of Hong Kong, with sponsorship support from HuggingFace and fal.ai.
Image Editing
76.7K
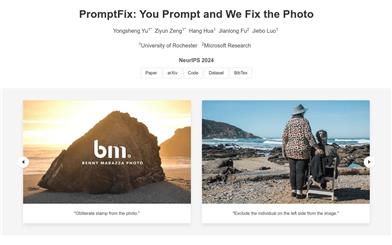
Promptfix
PromptFix is a comprehensive framework that enables diffusion models to perform various image processing tasks by following human instructions. This framework constructs a large-scale instruction-following dataset, proposes high-frequency guided sampling methods to control the denoising process while retaining high-frequency details in unprocessed areas, and designs auxiliary prompt adapters that enhance text prompts using visual language models, increasing the model's task generalization capabilities. PromptFix outperforms previous methods across various image processing tasks and demonstrates superior zero-shot capabilities in blind restoration and compositional tasks.
Image Editing
56.9K
Fastercache
FasterCache is an innovative no-training strategy designed to accelerate the inference process of video diffusion models while generating high-quality video content. The significance of this technology lies in its ability to significantly increase the efficiency of video generation while maintaining or enhancing content quality, making it extremely valuable for industries that require rapid video content production. FasterCache was jointly developed by researchers from the University of Hong Kong, Nanyang Technological University, and the Shanghai Artificial Intelligence Laboratory, with the project page offering more visual results and detailed information. The product is currently available for free, primarily targeting the fields of video content generation, AI research, and development.
Model Training and Deployment
49.4K
Hellomeme
HelloMeme is a diffusion model that incorporates spatially woven attention, designed to embed high fidelity and rich conditions into the image generation process. This technology generates videos by extracting features from each frame of the driving video and using them as input to the HMControlModule. Further optimization through the Animatediff module improves the continuity and fidelity of the generated videos. Additionally, HelloMeme supports facial expression control through ARKit's blend shapes, and enables the seamless integration of SD1.5-based Lora or Checkpoint, ensuring that it does not compromise the generalization ability of the T2I model.
AI image generation
58.5K
Diffusers Image Outpaint
Diffusers Image Outpaint is an image extension technology based on diffusion models, capable of generating additional parts of an image based on existing content. This technology has broad application prospects in fields such as image editing, game development, and virtual reality. Utilizing advanced machine learning algorithms, it makes image generation more natural and realistic, offering users an innovative way to process images.
AI image generation
90.3K
Omnigen
OmniGen is an innovative diffusion framework that consolidates various image generation tasks into a single model, eliminating the need for task-specific networks or fine-tuning. This technology simplifies the image generation workflow, enhances efficiency, and reduces development and maintenance costs.
AI image generation
182.7K

Concept Sliders
Concept Sliders is a technique for precisely controlling concepts in diffusion models, implemented through low-rank adapters (LoRA) on top of pre-trained models. It allows artists and users to train directional control over specific attributes using simple text descriptions or image pairs. The main advantage of this technology is its ability to make subtle adjustments to generated images without altering their overall structure, such as modifying eye size or lighting, thus achieving finer control. It provides artists with a new means of creative expression while addressing issues of generating blurry or distorted images.
AI design tools
51.6K
Dipir
DiPIR is a physics-based method co-developed by the Toronto AI Lab and NVIDIA Research, which recovers scene lighting from a single image, allowing virtual objects to be inserted realistically into both indoor and outdoor scenes. This technology not only optimizes material and tone mapping but also automatically adjusts to different environments to enhance the realism of the images.
AI image generation
51.1K
Ml Mdm
ml-mdm is a Python package designed for the efficient training of high-quality text-to-image diffusion models. Utilizing Matryoshka diffusion model technology, it can train a single pixel-space model at a resolution of 1024x1024 pixels, demonstrating impressive zero-shot generalization capabilities.
AI image generation
54.4K
Dit MoE
DiT-MoE is a diffusion transformer model implemented in PyTorch that can scale up to 16 billion parameters while competing with dense networks and demonstrating highly optimized inference capabilities. It represents cutting-edge technology in deep learning for handling large-scale datasets, carrying significant research and application value.
AI Model
50.5K
Fresh Picks

Tryondiffusion
TryOnDiffusion is an innovative image synthesis technology that uses a combination of two UNets (Parallel-UNet) to simultaneously maintain clothing details and accommodate significant variations in body posture and shape within a single network. This technology addresses the limitations of previous methods in balancing detail preservation and pose adaptation, achieving industry-leading performance.
AI image generation
66.5K
DIAMOND
DIAMOND (DIffusion As a Model Of eNvironment Dreams) is a reinforcement learning agent trained in a diffusion world model for visually-rich worlds crucial to Atari games. Trained on a subset of Atari games using autoregressive imagination, it offers quick installation and allows users to experiment with pre-trained world models.
AI Model
48.3K
- 1
- 2
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M